Implementing TCP Prague in ns-3
This page summarizes my work done from June 2020 - August 2020 with the ns-3 Network Simulator as part of Google Summer of Code 2020.
I thank Tom Henderson, Ankit Deepak, Mohit Tahiliani, Vivek Jain, Viyom Mittal for assisting me with the project goals and directions. I also thank Bob Briscoe, Olivier Tilmans and Asad Sajjad Ahmed for the many useful email discussions about Prague.
I am grateful to ns-3 for accepting my project proposal, and to Google for funding me throughout the project.
Table of Contents
- Introduction and Motivation
- Project Overview and Contributions
- Phase 1: Dynamic Pacing Rate
- Phase 2: RTT Independence
- Phase 3: Alignment with Linux
- Conclusion
- Future Work
- References
Introduction and Motivation
The Low Latency, Low Loss Scalable Throughput (L4S) architecture is designed to reduce latency for all Internet applications. In order to reduce queuing delay, this approach shifts the focus from optimizing Active Queue Management (AQM) towards introducing newer techniques in the TCP. The core objective here is to use a congestion control mechanism that scales with RTT and network link speeds.
Existing TCP congestion controls such as Reno and Cubic can perform badly in high-speed networks because of their slow response with large congestion windows. These non-scalable congestion controls fail to better utilize networks with high bandwidth-delay products. Scalable TCP offers a robust mechanism to improve this performance using traditional TCP receivers without interacting badly with existing traffic.
With this in mind, scalable congestion controls such as Data Center TCP (DCTCP) already exist. However, there are several problems if DCTCP was deployed on the Internet: for example, if DCTCP flows and Reno-like flows were to share a common queue, DCTCP increases the rate of ECN marking and Reno-like flows would reduce their throughput by a larger margin leading to unfairness between the two kinds of flows.
Therefore, several new features are added to DCTCP to allow it to be deployed on the internet, in a Reno-friendly way. To state a few,
- The L4S service traffic needs to be isolated from the queuing delay of the Classic service traffic.
- The host needs to distinguish L4S and Classic packets with an identifier.
All these additional modifications over DCTCP have been drafted into a new protocol called TCP Prague, that aims to integrate scalable congestion controls into the Internet by providing many safety mechanisms that allow it to coexist with current Classic protocols. These modifications include Accurate ECN feedback, Pacing, RTT Independence, Classic ECN AQM detection, and are highlighted in the following figure.

Project Overview and Contributions
At the time of this work, TCP Prague did not have a well defined IETF draft. Therefore, our primary goal was to align the ns-3 implementation of Prague with that of Linux. The L4S Team led by Bob Briscoe already had a Linux implementation of TCP Prague which was being tested separately, and wasn’t yet merged into mainline Linux kernel. The current ns-3 Prague version follows this commit of their Linux implementation.
On a higher level, this project was divided into three phases each spanning a month. The following objectives were successfully achieved in each phase:
- Phase 1: Add dynamic pacing rate to ns-3 TCP
- Phase 2: Implement RTT independence in ns-3 DCTCP
- Phase 3: Extend ns-3 Prague from ns-3 DCTCP aligned with Linux Prague
Phase 1: Dynamic Pacing Rate
Link to code:
https://gitlab.com/deepakkavoor/ns-3-dev/-/commits/pacing-mr
In order to decrease pressure on the bottleneck queue and reduce frequent congestion marks, it is important for a Prague sender to pace out packets during transmission. Although ns-3 already had the pacing feature in TCP prior to this phase, one could only configure a fixed pacing rate which would be followed throughout the simulation.
In this phase, I worked on allowing the pacing rate to change dynamically based on current congestion window and RTT measurement. Our experiments also showed that enabling this dynamic behaviour prevented situations in which a Prague sender received an eary mark during Slow Start. This feature is present in Linux, and adding it to ns-3 was a valuable contribution towards aligning ns-3 Prague with Linux.
The pacing rate is updated as follows.
pacingRate = factor * cWnd / RTT
The value of factor can be manually configured, and can be different depending on whether TCP is in Slow Start or Congestion Avoidance.
During Slow Start, Linux uses a default value of factor = 2 (which allows TCP to probe for higher speeds) and factor = 1 during Congestion Avoidance. The same default parameters are used in ns-3.
A test suite was also added that confirms whether packets are being paced out at the correct rate, depending on whether the sender TCP is currently in Slow Start or Congestion Avoidance.
Phase 2: RTT Independence
Link to code:
https://gitlab.com/deepakkavoor/ns-3-dev/-/commits/prague-mr
Prague, being a scalable congestion control, tends to experience low queuing delays due to its responsive nature. This leads to lower RTT, meaning that a Prague sender changes its congestion window more frequently.
If Prague and a Classic flow such as Reno were to exist simultaneously with a common bottleneck, Prague would thus have a bigger share of the bandwidth and experience more throughput compared to Reno.
Reducing RTT dependence allows us to remove this unfairness and safely deploy Prague over the internet. The idea here is to scale cWnd growth during Congestion Avoidance, so that both flows now reasonably converge to a common throughput.
First, we set a parameter targetRTT (with a default of 15ms) denoting the RTT in which Prague is expected to operate in. This means that cWnd is updated in such a way that Prague is fair to a flow operating with an RTT of 15ms.
Suppose the actual RTT that Prague experiences is curRTT. Ideally the cWnd increment (in segments) for every ACK during Congestion Avoidance would be
increment = 1 / cWnd
which would lead to an overall increase of 1 segment per RTT. If we enable RTT independence, the new increment would look like
increment = (curRTT / targetRTT) * (curRTT / targetRTT) * 1 / cWnd
To explain better, let’s take an example: suppose curRTT = 5ms, targetRTT = 15ms, cWnd = 10 segments. Based on targetRTT, we should expect an increase of 1 segment in 15ms to ensure fairness.
-
RTT independence disabled: The actual RTT being 5ms,
cWndis increased by 1 segment for every 5ms (based on the original update equation during Congestion Avoidance). This means thatcWndis increased by 3 segments in 15ms, leading to unfairness with a Classic flow whose actual RTT is 15ms andcWndincrease per RTT is 1 segment. -
RTT independence enabled:
-
Let’s see the significance of the first factor in the modified update equation. In this case,
cWndis increased by(1 / 3) * 1 / cWndfor every ACK, meaning thatcWndis increased by 1 / 3 segments in 5ms and consequently by 1 segment in 15ms. This is the expected increase for a Reno flow with RTT 15ms. -
The second factor is also equally important. With only the first factor, Prague and Reno (with say
cWnd= 10 segments for each and RTTs 5ms and 15ms respectively) now updatecWndby equal amounts per ACK. However, the update frequency is higher in case of Prague (due to its lower RTT). More concretely, the number of timescWndis incrememted in case of Reno per 15ms is 10, whereas Prague incrementscWnd10 times per 5ms and hence 30 times per 15ms. Let us sayincrease in throughput = no. of times cWnd is updated * cWnd increment each timeNote that the increase in throughput for Reno is 10 * 1 = 10 segments per 15ms, and for Prague is 30 * 1 = 30 segments per 15ms. If we indeed used the second factor,
cWndincrease per ACK for Prague would be1 / 9 * 1 / cWnd(the increase per 15ms would be 1 / 3), and hence the increase in throughput would be 30 * 1 / 3 = 10 segments per 15ms.
-
There are different types of RTT Scaling heuristics used, and the increment equation mentioned before refers to the “Rate Control” heuristic. For other heuristics like “Scalable” and “Additive”, one can refer to the code linked above.
Phase 3: Alignment with Linux
Link to code:
https://gitlab.com/deepakkavoor/ns-3-dev/-/commits/prague-mr
Alignment in the one-flow scenario:
https://drive.google.com/drive/folders/1qUhWiFwFO9eM8JQZWinMoD2TZVkC4Ca-
Alignment in the two-flow scenario:
https://drive.google.com/drive/folders/1hBZ2SUlfSWEO1gRhXeUmGfAzXmd8DRGJ
The features from Phases 1 and 2 were implemented on top of ns-3 Prague, which was very similar in structure to ns-3 DCTCP (except that ns-3 Prague used the ECT(1) codepoint). During this phase, the ns-3 Prague code was heavily refactored to match the Linux implementation.
We decided to validate ns-3 Prague with that of Linux using Network Namespaces. The topology scenarios used to validate our implementation were chosen from Pete Heist’s experiments, which compared the L4S architecture against SCE using Linux namespaces as well.
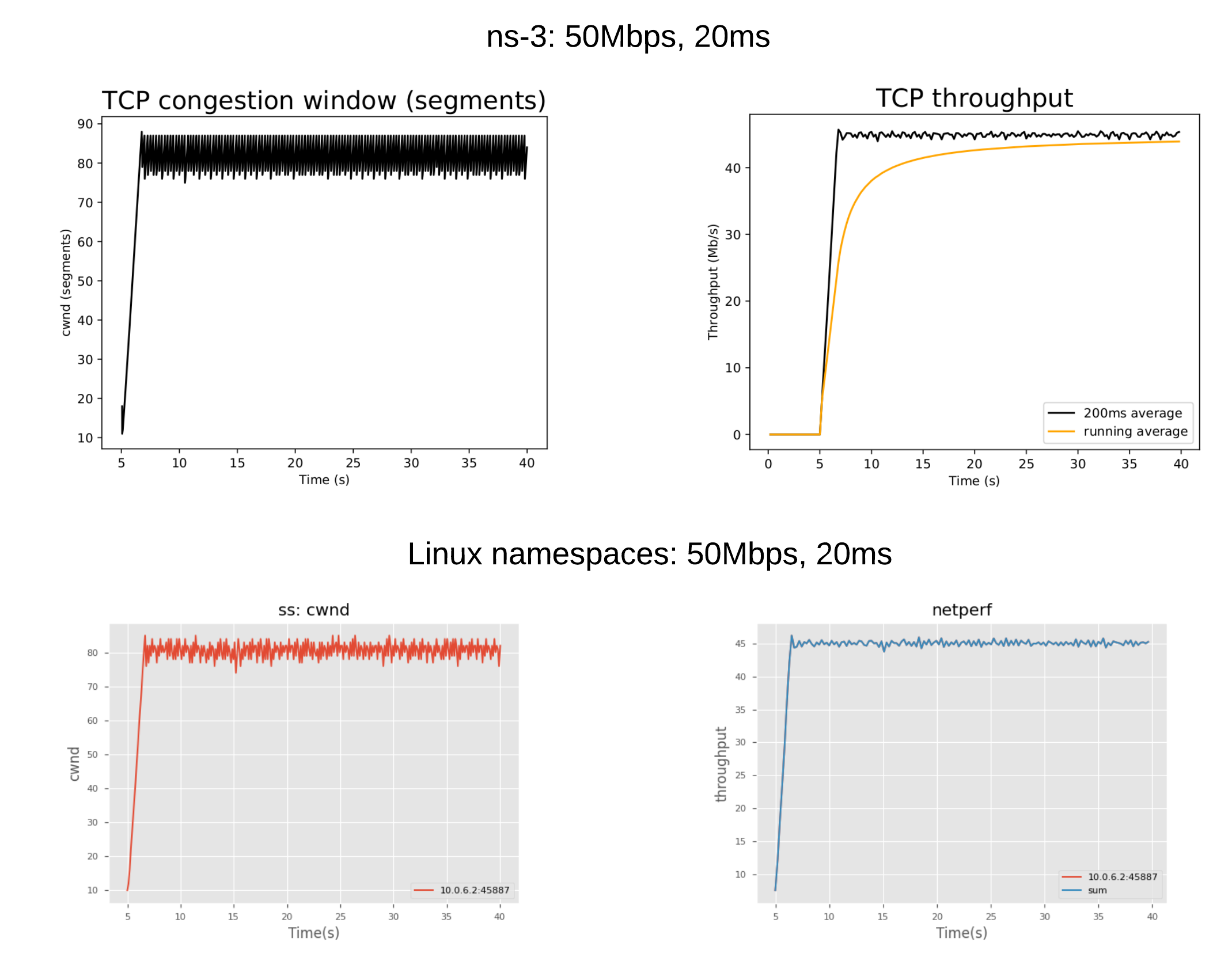
The one-flow scenario contains a Prague sender, five routers and a Prague receiver. All nodes except two routers use an FqCoDel queue disc, one router uses FIFO, and one uses the Dual-Queue Coupled AQM. The bottleneck bandwidth and RTT varied between 5Mbps, 50Mbps, 250Mbps and 20ms, 80ms, 160ms respectively. We used NeST to build this topology in Linux namespaces, and the ns-3 l4s-evaluation suite to run the one-flow scenario in ns-3. The plots obtained in Linux and ns-3 for different values of bottleneck bandwidth and RTT values were compared with each other.
The two-flow scenario was used to validate the RTT independence feature of ns-3 Prague with that of Linux. This topology is an extension of the previous one, with an addition of a Reno server and a Reno client sharing the same bottleneck as Prague. The bottleneck was fixed to be 50Mbps, and RTT varied between 500us, 5ms, 15ms, 200ms. Once again, NeST and the l4s-evaluation suite were used to obtain plots for comparison.
We obtained closely aligning results between ns-3 and Linux for both the one-flow and two-flow scenarios. The corresponding plots and results can be found in the two Google Drive links attached above.
For instance, the following figure shows alignment between ns-3 Prague and Linux Prague with the one-flow scenario, bottleneck of 50Mbps and an RTT of 20ms.
Conclusion
Since TCP Prague is still actively being researched and debated about, a network simulator such as ns-3 would allow easy reproducibility of results and more importantly allow researchers to try different possibilities in search of improvements.
We hope that the alignment results obtained in this project provide a motivation to use ns-3 more extensively for research and development of future modifications over TCP Prague.
Future Work
There is still more work to be done in order to fully align ns-3 Prague with Linux. Accurate ECN (AccECN) feedback is currently absent in ns-3, and its addition would allow ns-3 Prague to identify congestion in the network with more precision. AccECN is currently present in Linux Prague, and is a requirement for the end nodes to use Prague.
Classic ECN detection is another feature absent in mainline ns-3 Prague. This feature would allow Prague to detect if it shares (with a non-scalable congestion control) a common bottleneck queue that supports only classic ECN. In that case, Prague would reduce its congestion window appropriately by a larger value to ensure fairness. This feature is currently present in Linux.
References
[1] Low Latency, Low Loss, Scalable Throughput (L4S) Internet Service: Architecture
[2] Implementing the ‘Prague Requirements’ for Low Latency Low Loss Scalable Throughput (L4S)
[3] Resolving Tensions between Congestion Control Scaling Requirements
[4] Slides from the TSVWG IETF Interim Meeting, February 2020
[5] TCP Prague Fall-back on Detection of a Classic ECN AQM